本文最后更新于:June 30, 2023 pm
本文作者:[wangwenhai] # 概要:本文主要讲解Erlang的Web框架Cowboy的基础使用
1.Cowboy简介
Cowboy是Erlang的一个Web 服务器框架,比较精简,适合嵌入式WEB服务器系统开发,目前Cowboy在Erlang世界用的比较多,但是中文资料确实不多。为了方便学习,本人将Cowboy官网的文档来做一个简短的解读,方便新手学习,因为本人能力有限,如有错误请联系指出。
Cowboy关注于构建HTTP服务器,而非基于HTTP的业务系统。所以Cowboy讲的东西大部分比较底层,甚至晦涩,需要我们读者有扎实的HTTP基础。
2.Cowboy安装
2.1 Makefile形式
- 首先,新一个目录,用来存放我们的应用:
mkdir hello_erlang
cd hello_erlang
wget https://erlang.mk/erlang.mk
make -f erlang.mk bootstrap bootstrap-rel
make run
...
(hello_erlang@127.0.0.1)1>输入i()命令可查看正在运行的进程数据。以上步骤没有做任何事,仅仅是启动了一个节点。
接下来配置Cowboy,打开Makefile:
PROJECT = hello_erlang DEPS = cowboy dep_cowboy_commit = 2.7.0 DEP_PLUGINS = cowboy include erlang.mk执行make run,Cowboy就会被编译进你的项目里面。
2.2 Rebar构建。
Rebar是Erlang的构建工具,类似于Maven和NPM,目前最新版是Rebar3,本教程就按照Rebar3的形式进行演示。
新建项目
mkdir demo cd demo rebar3 new release demo此时Rebar3会帮我们自动化创建项目结构
===> Writing demo/apps/demo/src/demo_app.erl ===> Writing demo/apps/demo/src/demo_sup.erl ===> Writing demo/apps/demo/src/demo.app.src ===> Writing demo/rebar.config ===> Writing demo/config/sys.config ===> Writing demo/config/vm.args ===> Writing demo/.gitignore ===> Writing demo/LICENSE ===> Writing demo/README.md加入Cowboy依赖
我们打开rebar.config,加入Cowboy的依赖{cowboy, "2.6.3", {git, "git://github.com/ninenines/cowboy.git", {tag, "2.6.3"}}},版本请自行选择。
{erl_opts, [debug_info]}.
{deps, [
{cowboy, "2.6.3", {git, "git://github.com/ninenines/cowboy.git", {tag, "2.6.3"}}},
]}.
{relx, [{release, {demo, "0.1.0"},
[trap,
stdlib,
sasl]},
{sys_config, "./config/sys.config"},
{vm_args, "./config/vm.args"},
{dev_mode, true},
{include_erts, false},
{extended_start_script, true}]
}.
{profiles, [{prod, [{relx, [{dev_mode, false},
{include_erts, true}]}]
}]
}.
- 编译
rebar3 compile
3.运行测试
上述流程完成以后,我们接下来测试一下Cowboy是否可以运行。找到项目下的app.erl,然后添加以下代码:
start(_Type, _Args) ->
Dispatch = cowboy_router:compile([
{'_', [{"/", hello_handler, []}]}
]),
{ok, _} = cowboy:start_clear(my_http_listener,
[{port, 8080}],
#{env => #{dispatch => Dispatch}}
),
demo_app_sup:start_link().这样我们就启动了一个监听器,接下来我们再新建一个handler处理器,来处理web请求:
执行命令:make new t=cowboy.http n=hello_handler,或者手动新建一个hello_handler.erl文件,加入代码:
init(Req0, State) ->
Req = cowboy_req:reply(200,
#{<<"content-type">> => <<"text/plain">>},
<<"Hello Erlang!">>,
Req0),
{ok, Req, State}.此时我们重新运行:rebar3 shell命令,即可进行调试,没有错误信息以后,浏览器打开http://localhost:8080,即可测试。
4.Listeners:端口监听器
本质上来说,端口监听器其实还是一个Socket处理器,负责客户端的连接处理,类似于Tomcat的Connector。
下面我们分别启动一个最简单的HTTP服务器和HTTPS服务器。
4.1 HTTP服务器
start(_Type, _Args) ->
Dispatch = cowboy_router:compile([
{'_', [{"/", hello_handler, []}]}
]),
{ok, _} = cowboy:start_clear(my_http_listener,
[{port, 8080}],
#{env => #{dispatch => Dispatch}}
).
%% 其它代码上面给出的代码启动了一个最简单的HTTP服务器,监听8080端口,项目路径是根目录/。
4.2 HTTPS服务器
start(_Type, _Args) ->
Dispatch = cowboy_router:compile([
{'_', [{"/", hello_handler, []}]}
]),
{ok, _} = cowboy:start_tls(my_https_listener,
[
{port, 8443},
{certfile, "/path/to/certfile"},
{keyfile, "/path/to/keyfile"}
],
#{env => #{dispatch => Dispatch}}
),
%% 其它代码HTTPS服务器和HTTP不同的是,需要指定HTTPS的真证书路径:
{certfile, "/path/to/certfile"},
{keyfile, "/path/to/keyfile"}HTTP/1.1和HTTP/2协议共享相同的语义(可以查看HTTP RFC相关定义);只有他们的框架不同。HTTP1.1是文本协议,HTTP1.2是二进制协议。
Cowboy没有将HTTP/1.1和HTTP/2的配置分开。所有东西都在同一个Map上,配置选项是共享的。
4.3 代码简要分析
cowboy_router:compile用来构建路由,cowboy:start_XXX用来启动具体的服务器。
4.4 停止服务器
stop(_State) ->
ok = cowboy:stop_listener(my_http_listener).5.Routing:路由
如果你学过JavaEE,或许还记得Java的servlet的路由定义形式:首先定义一个类继承HttpServlet,然后重写Get或者Post方法,最后注册到容器里面。其实这就是web框架通用的一种做法,将一个执行模块提取出来,注册到一个路由下面,然后交给容器去调度。下面我们看一下Cowboy的路由,你会发现其实和JavaEE,Python的Django等框架类似,比较容易理解。
5.1 配置规则
路由的一般结构定义如下:
Routes = [Host1, Host2, ... HostN].分别给Host配置不同的规则:
Host1 = {HostMatch, PathsList}.
Host2 = {HostMatch, Constraints, PathsList}.配置路由表:
PathsList = [Path1, Path2, ... PathN].
路由模式匹配:
Path1 = {PathMatch, Handler, InitialState}.
Path2 = {PathMatch, Constraints, Handler, InitialState}.匹配规则
但级路径匹配:PathMatch1 = "/".
多级路径匹配:PathMatch2 = "/path/to/resource".
Host匹配:HostMatch1 = "cowboy.example.org".路径参数
PathMatch = "/hats/:name/prices".
HostMatch = ":subdomain.example.org".其中:name是路径参数,:subdomain是域名参数。举个例子:
匹配域名domain1,name参数name1:
URL:http://domain1.example.org/hats/name1/prices
匹配域名domain2,name参数name2:
URL:http://domain2.example.org/hats/name2/prices
路径参数可以通过cowboy_req:binding/{2,3}来获取。其中有个特殊的匹配符号就是原子’_’,表示任意匹配。
可选路径参数
PathMatch = "/book/[:chapter]/[:page]".其中chapter,page都是可选字段。
5.2 URL统配符:[...]
PathMatch = "/hats/[...]".
HostMatch = "[...]ninenines.eu".[...]通配符可以用来获取匹配剩下的所有URL,例如URL:/a/b/c/e/f........,当配置了/a/[...]以后,匹配到的就是b/c/e/f.......后面的字符串。
5.3 特殊符号:
PathMatch1 = '_'.
HostMatch2 = '_'.
PathMatch3 = '*'.
HostMatch4 = '*'.'_'匹配所有的URL,'*'是个主机通配符,通常与OPTIONS方法一起使用,用在跨域请求场景下。
6.Constraints:约束条件
Cowboy这么定义约束条件:匹配完成后,可以根据一组约束对结果绑定进行测试。只有在定义绑定时才测试约束。它们按照你定义的顺序运行。只有他们都成功,匹配才会成功。如果匹配失败,Cowboy将尝试列表中的下一条路由。约束使用的格式与cowboy_req中的匹配函数相同:它们作为可能有一个或多个约束的字段列表提供。虽然路由接受相同的格式,但它会跳过没有约束的字段,如果有默认值,也会忽略。
乍一看这个定义让人头大,如果你学过JavaWEB,肯定对值过滤比较熟悉,没错Cowboy的Constraints就是用来过滤合法值的。比如用户登陆的时候,判断email的合法性或者手机号码的合法性等等。SpringMVC里面叫验证器:Validator。
6.1 约束条件规范
约束条件以字段列表的形式提供。对于列表中的每个字段,可以应用特定的约束条件,如果字段缺失,还可以应用默认值。
字段可以是atom、带约束条件的的tuple {field, constraints}或带约束条件的tuple和默认值{field, constraints, default}的形式,其中field是必填的。
请注意,当与路由一起使用时,只有第二种形式是有意义的,因为它不使用默认值,并且field总是有值。每个字段的约束条件以原子或函数的有序列表的形式提供。内置约束条件是原子,而自定义约束条件是函数。
以下约束条件将首先验证并将字段my_value转换为整数,然后检查该整数是否为正:
PositiveFun = fun
(_, V) when V > 0 ->
{ok, V};
(_, _) ->
{error, not_positive}
end,
{my_value, [int, PositiveFun]}.内置约束条件:
| 条件约束 | 描述 |
|---|---|
| int | 将二进制值转换为整数 |
| nonempty | 确保二进制值不为空 |
6.2 自定义约束条件
自定义约束是一个函数。这个函数有两个参数。第一个参数表示要执行的操作,第二个参数是值。值是什么以及必须返回什么取决于操作。 Cowboy目前定义三个操作。用于验证和转换用户输入的操作是 forward 操作。
int(forward, Value) ->
try
{ok, binary_to_integer(Value)}
catch _:_ ->
{error, not_an_integer}
end;即使没有约束条件,Value也依序被返回。
reverse 的操作则相反:它获取一个转换后的值并将其返回回用户输入的值 。其实就是类型转换。
int(reverse, Value) ->
try
{ok, integer_to_binary(Value)}
catch _:_ ->
{error, not_an_integer}
end; 最后,format_error操作接受任何其他操作返回的错误,并返回格式化的可读的错误消息。 主要用来返回条件约束处理错误的信息。
int(format_error, {not_an_integer, Value}) ->
io_lib:format("The value ~p is not an integer.", [Value]).Cowboy不会捕获来自约束函数的异常。它们应该被编写成不抛出任何异常。
7.Handlers:请求处理器
到这部分就容易理解了,其实对应的就是SpringMVC的Controller。学习这一节之前,我们再来回顾一下JavaEE一些旧知识点。
首先我们写一个简单的JavaServlet。
class HttpServlet extends javax.servlet.http.HttpServlet{
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
System.out.println("helloWorld");
super.doGet(req, resp);
}
}上述代码中我们实现了javax.servlet.http.HttpServlet类,重写了doGet方法。这其实就是一个典型的HTTP处理过程。
接下来我们换到Cowboy,实现一个同样功能的处理器
-module(index_handler).
-author("wangwenhai").
-behaviour(cowboy_handler).
%% API-export([init/2, terminate/3]).
-record(state, {}).
init(Req0, State) ->
Req = cowboy_req:reply(200, #{
<<"content-type">> => <<"text/plain">>
}, <<"Hello World!">>, Req0),
{ok, Req, State}.
terminate(_Reason, _Req, _State) ->
ok.
认真观察一下两处代码的共同之处:
Java和Cowboy都实现了某个模块,或者类
二者都实现了某个特定的函数
对于Cowboy而言,则是实现了特定的行为模式(行为模式是Erlatng的语法特性,请自行学习相关知识):-behaviour(cowboy_handler).,然后重写了init和terminate。返回值为:{ok, Reply, State},Reply通过cowboy_req:reply构建。
所有处理程序类型都提供可选的terminate/3回调。 需要注意的是,此函数只要调用,表示当前处理器已经被销毁,我们不可以在这里写自己的业务逻辑。
terminate(_Reason, _Req, _State) ->
ok.8.Loop handlers:循环处理器
到目前未知,个人感觉这一节是最陌生的。貌似我在做JavaWeb的时候,压根没听过循环处理器这种说法。我们直接翻译官方的说明看看:
循环处理程序是一种特殊类型的HTTP处理程序,用于无法立即发送响应。处理程序进入一个接收循环,等待正确的消息,然后才能发送响应。
循环处理程序用于这样的请求:响应可能不是立即可用的,但是您希望在响应到达时保持连接打开一段时间。这种实践最著名的例子是长轮询。循环处理程序也可以用于响应部分可用的请求,并且您需要在连接打开时传输响应主体。这种实践最著名的例子是服务器发送的事件,但是它也适用于任何需要很长时间发送的响应。虽然可以使用普通的HTTP处理程序来完成相同的工作,但是建议使用循环处理程序,因为它们经过了良好的测试,并且允许使用内置特性,比如休眠和超时。
哪怕是读到这里都感觉头大:我还是不理解这个循环处理器是什么用途?认证想了一下,貌似这种场景我们经常遇到,但是平时的项目开发中却很少见,我也比较新奇。大家设想一下这个场景:我们肯定有使用过一些在线处理图片或者压缩文件的网站,我们压缩比较大的文件的时候,速度会比较慢,比如压缩文件会让我们等待1分钟。这种场景表示的就是耗时操作,而Cowboy把这个叫:循环处理器。
理解了这个场景以后,其实就很容易使用它。循环处理器就是特殊的Handler而已,只不过init/2函数必须返回一个 cowboy_loop 原子,如下所示:
init(Req, State) ->
{cowboy_loop, Req, State}.同样我们如果要终止请求,可以使用hibernate:
init(Req, State) ->
{cowboy_loop, Req, State, hibernate}.初始化后,Cowboy将等待进程消息到达进程邮箱。当消息到达时,Cowboy调用info/3函数 。 下面的代码段在从另一个进程接收到应答消息时发送应答,或者在其他情况下等待另一个消息。
info({reply, Body}, Req, State) ->
cowboy_req:reply(200, #{}, Body, Req),
{stop, Req, State};
info(_Msg, Req, State) ->
{ok, Req, State, hibernate}.请注意,这里的应答元组可以是任何消息,它只是一个示例。 此回调可以执行任何必要的操作,包括发送应答的全部或部分,并随后返回一个tuple,该tuple表示是否需要发送更多消息。 回调也可以选择什么都不做,直接跳过接收到的消息。 如果发送了应答,那么应该返回stop元组。这将指定Cowboy结束请求。 否则应该返回一个ok元组 。
另一个非常适合循环处理程序的常见情况是以Erlang消息的形式接收流式数据。这可以通过在init/2回调中初始化一个 块(chunk)应答,然后在每次接收到消息时使用cowboy_req:chunk/2来实现。
从下面的代码片段可以看到,每次接收到事件消息时都会发送一个块(chunk),而通过发送eof消息来停止循环。
init(Req, State) ->
Req2 = cowboy_req:stream_reply(200, Req),
{cowboy_loop, Req2, State}.
info(eof, Req, State) ->
{stop, Req, State};
info({event, Data}, Req, State) ->
cowboy_req:stream_body(Data, nofin, Req),
{ok, Req, State};
info(_Msg, Req, State) ->
{ok, Req, State}. 为了节省内存,可以在接收到的消息之间休眠进程。这是通过作为循环元组回调的一部分返回原子hibernate来实现的。只要在最后添加一个原子,Cowboy就会相应休眠。
下面是cowboy_req:stream_reply的定义。 报头名称必须以小写二进制字符串的形式给出。虽然标题名不区分大小写,但Cowboy要求将它们以小写形式给出才能正常工作。 详细请看:https://ninenines.eu/docs/en/cowboy/2.7/manual/cowboy_req.stream_reply/
stream_reply(Status, Req :: cowboy_req:req())
-> stream_reply(StatusCode, #{}, Req)
stream_reply(Status, Headers, Req :: cowboy_req:req())
-> Req
Status :: cowboy:http_status()
Headers :: cowboy:http_headers()这一节讲的比较晦涩,其实我本人也是对块的概念不熟悉,其他项目的框架不会涉及到这些,因此这里只做了简单的讲解和部分概念直接翻译,后期加深框架了解以后方可更新本章。同时欢迎对本章内容熟悉的朋友提出修改建议。
9.Static files:静态资源
静态资源想必大家都比较熟悉了,常见的静态资源比如模板引擎,配置文件,JS脚本,CSS文件等等。本章主要就是讲解Cowboy如何处理静态文件。
Cowboy附带了一个随时可用的处理程序来提供静态文件。它的提供是为了方便在开发过程中为文件提供服务。对于生产中的系统,请考虑使用市场上提供的众多内容分发网络(CDN)中的一种,因为它们是提供文件的最佳解决方案。
静态处理程序可以为给定目录中的一个文件或所有文件提供服务。可以配置etag生成和mime类型。
可以使用静态处理程序从应用程序的私有目录提供一个特定的文件,当客户端请求/路径时返回一个index.html文件是一个不错的选择,相当于是一个默认页面。静态文件的路径定式应用程序私有的的相对目录。下面的案例将在访问路径/时从应用程序my_app的私有目录读取文件static/index.html。
9.1 相对路径的形式:
{"/", cowboy_static, {priv_file, my_app, "static/index.html"}}访问 / 路径的时候,返回my_qpp/static/index.html,其中my_app是我们的项目。
9.2 绝对路径的形式:
{"/", cowboy_static, {file, "/var/www/index.html"}}访问 / 路径的时候,返回/var/www/index.html,可以任意指定路径。
注意:priv_file原子和file是不一样的。
以上是最简单的静态文件处理方式,因为就一个index.html文件。接下来我们继续看一下如何以一个目录作为静态资源容器。
9.3 相对路径的形式:
{"/assets/[...]", cowboy_static, {priv_dir, my_app, "static/assets"}}访问 / 下某个文件的时候,Cowboy从
my_app/static/assets目录中开始查找文件,如果存在就返回,其中my_app是我们的项目。
9.4 绝对路径的形式:
{"/assets/[...]", cowboy_static, {dir, "/var/www/assets"}}访问 / 下某个文件的时候,Cowboy从
/var/www/assets目录中开始查找文件,如果存在就返回,其中/var/www/assets是我们的磁盘的绝对路径。
除此之外,我们还可以自定义MimeType。
MIME (Multipurpose Internet Mail Extensions) 是描述消息内容类型的因特网标准,说白了也就是文件的媒体类型。浏览器可以根据它来区分文件,然后决定什么内容用什么形式来显示。
我们可以通过浏览器查看MimeType,按下浏览器界面下的F12:
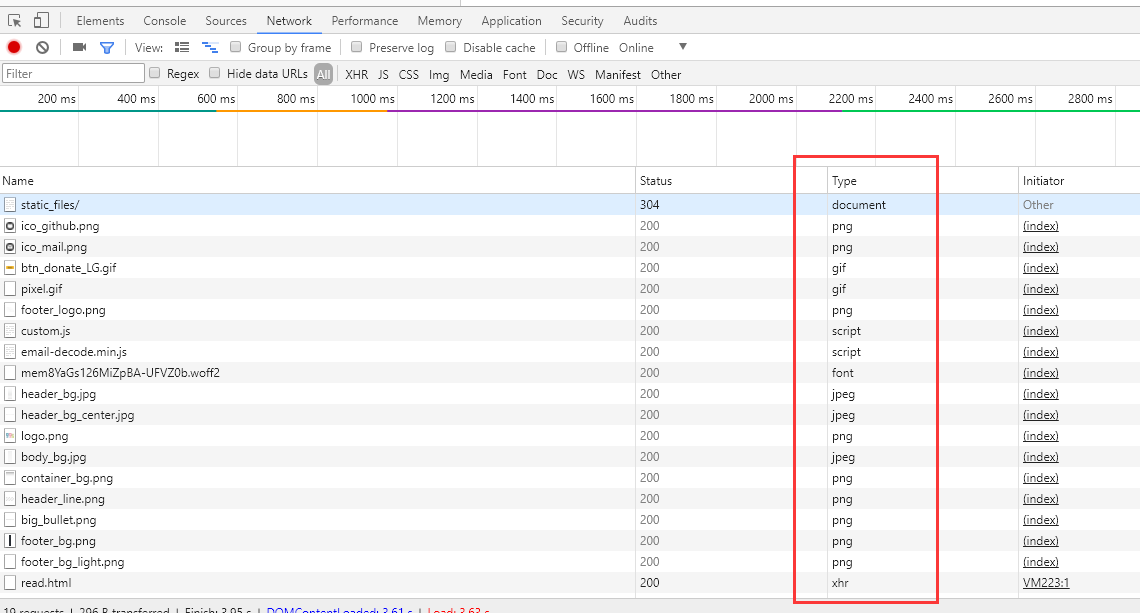
常见的MimeType:
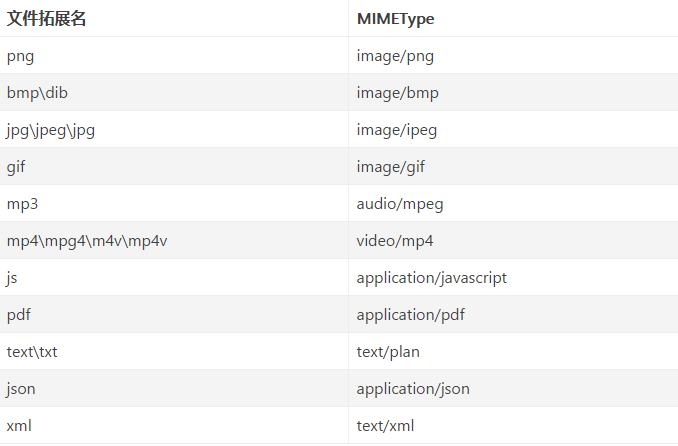
默认情况下,Cowboy将通过查看扩展名尝试识别静态文件的mimetype 。 我们可以重写关联静态文件的mimetype的函数。当Cowboy缺少需要处理的mimetype时,或者当希望减少列表以加快查找速度时,它非常有用。您还可以提供一个硬编码的mimetype,它将被无条件地使用。
Cowboy有两个内置函数。默认函数只处理构建Web应用程序时使用的常见文件类型。另一个函数是一个包含数百个mimetypes的扩展列表,可以满足我们几乎所有需求。当然,我们可以创建自己的函数。
要使用默认函数,我们不需要配置任何东西,因为它是默认的。如果你确实需要自定义Mimetype的话,下面的方法就可以了 。
本段直接翻译官网文档。
{"/assets/[...]", cowboy_static, {priv_dir, my_app, "static/assets",
[{mimetypes, cow_mimetypes, web}]}}如您所见,有一个可选字段可能包含一个较少使用的选项列表,如mimetypes或etag。所有选项类型都有这个可选字段。 要使用几乎可以检测所有mimetype的函数,可以执行以下配置 :
{"/assets/[...]", cowboy_static, {priv_dir, my_app, "static/assets",
[{mimetypes, cow_mimetypes, all}]}}通过上述代码我们发现:配置需要一个模块和一个函数名,因此可以使用自己的任何函数 。
{"/assets/[...]", cowboy_static, {priv_dir, my_app, "static/assets",
[{mimetypes, Module, Function}]}}Function就是我们需要处理MimeType的自定义函数。
执行mimetype检测的函数接收一个参数,该参数是磁盘上文件的路径。建议以元组形式返回mimetype,但也允许使用二进制字符串(但需要额外的处理)。如果函数找不到mimetype,则返回{< “application”>>, <<”octet-stream”>>,[]}。 当静态处理程序找不到扩展名时,它将以application/octet-stream的形式发送文件。接收到该文件的浏览器将尝试将其直接下载到磁盘。 最后,可以对所有文件硬编码mimetype。这是特别有用的组合文件和priv_file选项,因为它避免了不必要的计算。
{"/", cowboy_static, {priv_file, my_app, "static/index.html",
[{mimetypes, {<<"text">>, <<"html">>, []}}]}}本段直接翻译官网文档。
接下来看如何生成etag。
HTTP协议规格说明定义ETag为“被请求变量的实体值”。另一种说法是,ETag是一个可以与Web资源关联的记号(token)。典型的Web资源可以一个Web页,但也可能是JSON或XML文档。服务器单独负责判断记号是什么及其含义,并在HTTP响应头中将其传送到客户端,以下是服务器端返回的格式:ETag:”50b1c1d4f775c61:df3”客户端的查询更新格式是这样的:If-None-Match : W / “50b1c1d4f775c61:df3”如果ETag没改变,则返回状态304然后不返回,这也和Last-Modified一样。测试Etag主要在断点下载时比较有用。
默认情况下,静态处理程序将根据大小和修改时间生成etagHTTP请求头值。但是,这个解决方案不能适用于所有的系统。例如,它在节点集群上的性能相当差,因为文件元数据在不同服务器之间会有所不同,在每个服务器上提供不同的etag。 然而,你可以改变etag的计算方法:
{"/assets/[...]", cowboy_static, {priv_dir, my_app, "static/assets",
[{etag, Module, Function}]}}这个函数将接收三个参数:磁盘上文件的路径、文件大小和最后修改时间。在分布式设置中,通常使用文件路径来检索所有服务器上相同的etag值。
你也可以完全禁用etag处理 :
{"/assets/[...]", cowboy_static, {priv_dir, my_app, "static/assets",
[{etag, false}]}}本章内容讲的比较底层,涉及到了HTTP协议的一些东西。可能我们在开发项目的过程中,这些东西都用不到,文件也不会放到本地服务器上,一般都是CDN来处理,但是这章仍然可以作为大家拓展知识的一个章节。
10.Request details:客户端请求
这一节也是很好理解,学过Java的都知道HttpServletRequest,学PHP的都知道$_POST和$_GET。Cowboy把这部分内容封装成了Request。
Req对象是一个变量,用于获取关于请求、读取其主体或发送响应的信息。它实际上不是面向对象意义上的对象,其实是Erlang的一种数据结构,它是一个简单的映射,可以在从cowboy_req模块调用函数时直接访问或使用。
Req对象是几个不同章节的主题。在本章中,我们将学习Req对象,并了解如何检索关于请求的信息。
Req映射包含许多字段,这些字段已被文档化,可以直接访问。它们是直接映射到HTTP的字段:请求方法;使用的HTTP版本;有效的URI组件方案、主机、端口、路径和qs;请求头;连接的对等地址和端口;及TLS证书证书(如适用)。
请注意,version字段可用于确定连接是否使用HTTP/2。
上面是翻译过来的官网文档,其实对应的就类似于Java里面的HttpServletRequest:
public interface HttpServletRequest extends ServletRequest {
//省略代码
}
我们可以看到有很多获取客户端数据的方法,对应到Cocboy的Req对象,其实也是大同小异, 要访问字段,只需匹配函数头。下面的示例在方法为GET时发送一个简单的“Hello world!”响应,否则发送一个405错误。
init(Req0=#{method := <<"GET">>}, State) ->
Req = cowboy_req:reply(200, #{
<<"content-type">> => <<"text/plain">>
}, <<"Hello world!">>, Req0),
{ok, Req, State};
init(Req0, State) ->
Req = cowboy_req:reply(405, #{
<<"allow">> => <<"GET">>
}, Req0),
{ok, Req, State}.任何其他字段都是内部的,不应该被访问。它们可能会在未来的版本(包括维护版本)中发生变化,而不另行通知。
虽然允许修改Req对象,但除非绝对必要,否则不建议修改。如果添加了新字段,请确保对字段名称命名空间,这样就不会与未来的Cowboy更新或第三方项目发生冲突。对比Java,可以理解为私有的数据不能被随便修改,是只读属性。
10.1 cowboy_req接口简介
cowboy_req模块中的函数提供对请求信息的访问,以及处理HTTP请求时常见的各种操作。以动词开头的所有函数都表示动作。其他函数只是返回相应的值(有时确实需要构建该值,但是操作的成本相当于检索一个值)。 一些cowboy_req函数返回一个更新的Req对象。它们是read、reply、set和delete函数。虽然忽略返回的Req不会导致某些错误的行为,但是强烈建议始终保留并使用最后一个返回的Req对象。cowboy_req的手册详细介绍了这些函数以及对Req对象所做的修改。对cowboy_req的一些调用有副作用。这是read和reply函数的情况。Cowboy读取请求体,或者在调用函数时立即响应。如果出了问题,所有的函数都会崩溃。通常不需要捕获这些错误,Cowboy将根据崩溃发生的位置发送适当的4xx或5xx响应。
本段直接翻译文档
10.2 获取请求方法
通过记录获取:
#{method := Method} = Req.或者直接获取:
Method = cowboy_req:method(Req).该方法是区分大小写的二进制字符串。标准方法包括GET、HEAD、OPTIONS、PATCH、POST、PUT或DELETE。
10.3 HTTP版本
HTTP版本是信息性( informational :这个单词我不知道怎么翻译好,个人理解是:版本是个规范,有没有实现就是客户端的问题了)的。它并不表示客户机很好地或完全地实现了协议。通常不需要根据HTTP版本改变行为:Cowboy已经为您做了。不过,它在某些情况下可能有用。例如,您可能希望重定向HTTP/1.1客户端以使用Websocket,而HTTP/2客户端继续使用HTTP/2。
HTTP版本可以直接获取:
#{version := Version} = Req.或者通过函数获取:
Version = cowboy_req:version(Req).Cowboy定义了“HTTP/1.0”、“HTTP/1.1”和“HTTP/2”版本。自定义协议可以将自己的值定义为原子。
10.4 有效的请求URI
有效请求URI的请求方法、主机、端口、路径和查询字符串组件都可以直接获取:
#{
scheme := Scheme,
host := Host,
port := Port,
path := Path,
qs := Qs
} = Req.或者使用函数获取:
Scheme = cowboy_req:scheme(Req),
Host = cowboy_req:host(Req),
Port = cowboy_req:port(Req),
Path = cowboy_req:path(Req).
Qs = cowboy_req:qs(Req).HTTP请求方法和主机是大小写不敏感的二进制字符串。端口是表示端口号的整数。路径和查询字符串是区分大小写的二进制字符串。Cowboy只定义了<<”http”>>和<<”https”>>方案。它们被选中,因此对于安全HTTP/1.1或HTTP/2连接上的请求,该方案将仅为<<”https”>>。
有效的请求URI本身可以使用cowboy_req: URI /1,2函数进行重构。默认情况下,返回一个绝对URI:
%% scheme://host[:port]/path[?qs]
URI = cowboy_req:uri(Req).可以使用选项禁用或替换部分或全部组件。可以通过这种方式生成各种URI或URI格式,包括原始表单:
%% /path[?qs]
URI = cowboy_req:uri(Req, #{host => undefined}).协议相关的:
%% //host[:port]/path[?qs]
URI = cowboy_req:uri(Req, #{scheme => undefined}).查询字符串
URI = cowboy_req:uri(Req, #{qs => undefined}).Host:
URI = cowboy_req:uri(Req, #{host => <<"example.org">>}).10.5 绑定
绑定是在定义应用程序路由时选择提取的主机和路径组件。它们只在路由之后可用。
Cowboy提供一些函数去获取绑定的值。
获取单个值:
Value = cowboy_req:binding(userid, Req).默认值的情况:
Value = cowboy_req:binding(userid, Req, 42).获取所有绑定的值:
Bindings = cowboy_req:bindings(Req).它们作为映射返回,键是原子。Cowboy路由器还允许您使用...定符:
获取Host:
HostInfo = cowboy_req:host_info(Req).获取路径:
PathInfo = cowboy_req:path_info(Req). Cowboy将返回未定义如果...这条路线没有使用。
10.6 查询参数
Cowboy提供了两个函数来访问查询参数。您可以使用第一个参数来获得整个参数列表。
QsVals = cowboy_req:parse_qs(Req),
{_, Lang} = lists:keyfind(<<"lang">>, 1, QsVals).Cowboy只解析查询字符串,不进行任何转换。因此,这个函数可能返回重复的值,或者没有关联值的参数名。返回列表的顺序未定义。 当查询字符串key=1&key=2时,返回的列表将包含name key的两个参数。 当尝试使用php风格的后缀[]时也是如此。当查询字符串key[]=1&key[]=2时,返回的列表将包含name key[]的两个参数。 当查询字符串是简单的键时,Cowboy将返回列表[{<<”key”>>, true}],使用true表示参数键已定义,但没有值。 Cowboy提供的第二个函数允许您仅匹配感兴趣的参数,同时使用约束进行任何需要的后处理。这个函数返回一个映射。
#{id := ID, lang := Lang} = cowboy_req:match_qs([id, lang], Req).约束可以自动应用。当id参数不是整数或lang参数为空时,以下代码段将崩溃。同时,id的值将被转换为整数项:
QsMap = cowboy_req:match_qs([{id, int}, {lang, nonempty}], Req).也可以提供默认值。如果没有找到lang密钥,则使用默认值。如果找到的键值为空,则不会使用它。
#{lang := Lang} = cowboy_req:match_qs([{lang, [], <<"en-US">>}], Req).如果没有提供默认值,并且缺少该值,则查询字符串将被视为无效,进程将崩溃。当查询字符串key=1&key=2时,key的值将是列表[1,2]。参数名不需要包含php风格的后缀。可以使用约束来确保只传递一个值。
10.7 HTTP请求头
头值可以作为二进制字符串,也可以解析为更有意义的表示。
获取原始值:
HeaderVal = cowboy_req:header(<<"content-type">>, Req).Cowboy期望所有头名都以小写二进制字符串的形式提供。无论底层协议是什么,请求和响应都是如此。
当请求缺少header时,将返回undefined。可以提供一个不同的默认值:
HeaderVal = cowboy_req:header(<<"content-type">>, Req, <<"text/plain">>).所有的标题可以直接一次获取:
#{headers := AllHeaders} = Req.通过函数获取:
AllHeaders = cowboy_req:headers(Req).Cowboy提供了解析各个header的等效函数。没有一次解析所有标题的函数。
ParsedVal = cowboy_req:parse_header(<<"content-type">>, Req).如果不知道如何解析给定的HTTP请求头,或者该值无效,则会引发异常。已知HTTP请求头和默认值的列表可以在手册中找到。当头文件丢失时,将返回undefined。您可以更改默认值。注意,它应该是直接解析的值:
ParsedVal = cowboy_req:parse_header(<<"content-type">>, Req,
{<<"text">>, <<"plain">>, []}).10.8 Peer
这个单词我不知道怎么翻译,大家可以这么理解:服务器偷偷喵一眼客户端的基本信息。不过在网络里面有个peer的概念,表示的是点对点连接的两个端点,或许这里也是这个意思:获取连接客户端的基本信息
可以直接使用函数获取连接的对等地址和端口号:
#{peer := {IP, Port}} = Req.或者使用函数:
{IP, Port} = cowboy_req:peer(Req).请注意,对应到服务器的连接的远程端,服务器可能是客户机本身,也可能不是客户机本身。它也可以是代理或网关。
11.Reading the request body:请求体获取
可以使用Req对象读取body。Cowboy在请求之前不会试图读取body。您需要调用body读取函数来检索它。
Cowboy不会缓存body,因此只能读取一次。但是,你不需要读取body。如果存在未读的正文,Cowboy将根据协议取消或跳过其下载。Cowboy提供读取原始body、读取和解析urlenencoded或多部分body的函数。
11.1 判断请求体是否存在
如果有一个请求体,它返回true;否则错误。实际上,很少使用这个函数。当方法是POST、PUT或PATCH时,应用程序通常需要请求体,应用程序应该尝试直接读取它。
cowboy_req:has_body(Req).11.2 请求体的长度
Length = cowboy_req:body_length(Req).注意,长度可能不会提前知道。在这种情况下,undefined将被返回。这种情况可能发生在HTTP/1.1的分块传输编码中,或者在没有提供内容长度时发生在HTTP/2中。当读取完Req对象的主体后,Cowboy将更新该对象的主体长度。在完整读取主体后尝试调用此函数时,将始终返回一个长度。
11.3 读取Body
{ok, Data, Req} = cowboy_req:read_body(Req0).当body被完全读取时,Cowboy返回一个ok元组。默认情况下,Cowboy将尝试读取最多8MB的数据,最多持续15秒。一旦Cowboy读取了至少8MB的数据,或者在15秒周期结束时,调用将返回。
这些值可以定制。例如,读取最多1MB,最多5秒:
{ok, Data, Req} = cowboy_req:read_body(Req0,
#{length => 1000000, period => 5000}).你也可以禁用长度限制:
{ok, Data, Req} = cowboy_req:read_body(Req0, #{length => infinity}).这将使函数等待15秒并返回在此期间到达的所有内容。对于面向公众的应用程序,不建议这样做。这两个选项可以有效地用于控制请求体的传输速率。
11.4 流式处理Body
当Body太大时,第一个调用将返回更多的tuple而不是ok。可以再次调用该函数来读取更多的主体内容,一次读取一个块。
read_body_to_console(Req0) ->
case cowboy_req:read_body(Req0) of
{ok, Data, Req} ->
io:format("~s", [Data]),
Req;
{more, Data, Req} ->
io:format("~s", [Data]),
read_body_to_console(Req)
end.length和period选项被使用了,它们必须在每次调用的时候都被传递进去。
11.5 读取urlencoded body
Cowboy提供了一个便捷的函数,用于读取和解析以 application /x-www-form-urlencoded 发送的正文。
{ok, KeyValues, Req} = cowboy_req:read_urlencoded_body(Req0).这个函数返回一个键/值列表,与函数cowboy_req:parse_qs/1完全相同。这个函数的默认值是不同的。Cowboy将读取最多64KB和最多5秒。它可以调整:
{ok, KeyValues, Req} = cowboy_req:read_urlencoded_body(Req0,
#{length => 4096, period => 3000}).12.Sending a response:请求返回
请求返回也是很容易理解,每个WEB框架都有这个概念,我们还是继续拿Java的来讲,其实对应的就是HttpServletReponse:
class IndexServlet extends GenericServlet{
@Override
public void service(ServletRequest servletRequest, ServletResponse servletResponse) throws ServletException, IOException {
//servletResponse.xxx
}
}其他理论性的说明就不翻译了,我们直接看使用方法即可。
1. 一般返回值
设置HTTP状态码:
Response = cowboy_req:reply(200, Request).设置HTTP返回头:
Response = cowboy_req:reply(303, #{
<<"location">> => <<"https://ninenines.eu">>
}, Request).设置返回内容:
Response = cowboy_req:reply(200, #{
<<"content-type">> => <<"text/plain">>
}, "Hello world!", Request).响应体和标头值必须是二进制或iolist 。
构建多类型返回:
Title = "Hello world!",
Body = <<"Hats off!">>,
Response = cowboy_req:reply(200, #{
<<"content-type">> => <<"text/html">>
}, ["<html><head><title>", Title, "</title></head>",
"<body><p>", Body, "</p></body></html>"], Request).这种构建响应的方法比拼接字符串更有效。在后台,列表中的每个元素都只是一个指针,可以直接写入Socket。
2.字节流返回
Cowboy提供了两个用于初始化响应的函数,以及一个用于流化(数据转字节流)附加函数。Cowboy将向响应添加任何必需的头信息。当你只需要设置状态代码时,使用cowboy_req:stream_reply/2。
Response = cowboy_req:stream_reply(200, Requset),
cowboy_req:stream_body("Hello...", nofin, Req),
cowboy_req:stream_body("chunked...", nofin, Req),
cowboy_req:stream_body("world!!", fin, Req).cowboy_req的第二个参数:stream_body/3表示该数据是否终止该body。使用fin作为最后的标志,否则使用nofin。
此代码段没有设置内容类型标头。不建议这样做。具有正文的所有响应都应该具有内容类型。头可以预先设置,或使用cowboy_req:stream_reply/3:
Response = cowboy_req:stream_reply(200, #{
<<"content-type">> => <<"text/html">>
}, Request),
cowboy_req:stream_body("<html><head>Hello world!</head>", nofin, Request),
cowboy_req:stream_body("<body><p>Hats off!</p></body></html>", fin, Request).HTTP提供了一些不同的方法来流化响应主体。Cowboy将根据HTTP版本和请求和响应头选择最合适的一个。
虽然无论如何都不是必需的,但如果事先知道,建议在响应中设置content-length头。这将确保选择最佳响应方法,并帮助客户理解何时完全接收到响应。Cowboy还提供了发送响应片的功能。
Response = cowboy_req:stream_reply(200, #{
<<"content-type">> => <<"text/html">>,
<<"trailer">> => <<"expires, content-md5">>
}, Request),
cowboy_req:stream_body("<html><head>Hello world!</head>", nofin, Req),
cowboy_req:stream_body("<body><p>Hats off!</p></body></html>", nofin, Req),
cowboy_req:stream_trailers(#{
<<"expires">> => <<"Sun, 10 Dec 2017 19:13:47 GMT">>,
<<"content-md5">> => <<"c6081d20ff41a42ce17048ed1c0345e2">>
}, Response).其实就是用底层的方实构建HTTP的请求返回值。
3. 预设响应标头
Cowboy提供设置响应头而不立即发送它们的函数。它们存储在Req对象中,并在调用应答函数时作为响应的一部分发送。
设置响应标头:
Req = cowboy_req:set_resp_header(<<"allow">>, "GET", Req0).检查响应头是否已经设置:
cowboy_req:has_resp_header(<<"allow">>, Req).删除之前设置的响应标头:
Req = cowboy_req:delete_resp_header(<<"allow">>, Req0).4. 覆盖标头
因为Cowboy提供了不同的方法设置响应头和身体,可能发生冲突,因此当一个标头被设置两次以后会发生什么事情是很重要的。
标头有五种不同的来源:
- 协议规范的标头(比如HTTP版本)
- 其他标头(比如日期)
- 预设标头
- 返回函数给的标头
- Cookie标头
Cowboy不允许重写特定于协议的头文件。Set-cookie头信息总是在发送响应之前附加在头信息列表的末尾。
提供给应答函数的标头将始终覆盖预设标头和所需标头。如果在其中的两个或三个中发现一个标头,则选择应答函数中的标头,并删除其他标头。类似地,预置头将总是覆盖所需的头。
为了说明这一点,请看下面的代码片段。Cowboy默认发送值为“Cowboy”的服务器头。我们可以覆盖它:
Response = cowboy_req:reply(200, #{
<<"server">> => <<"yaws">>
}, Request).5.预设返回内容
Cowboy提供了一些函数来设置响应体,而不需要立即发送它。它存储在Req对象中,并在调用应答函数时发送。
设置响应主体:
Response = cowboy_req:set_resp_body("Hello world!", Request).查看是否已经设置了响应:
cowboy_req:has_resp_body(Request).如果主体设置为非空,则返回true,否则返回false。只有当使用的应答函数是cowboy_req:reply/2或cowboy_req:reply/3时,才会发送预设的响应体。
6.发送文件
Cowboy提供了发送文件的快捷方式。当使用cowboy_req:reply/4时,或者在预先设置响应头时,你可以给Cowboy一个sendfile元组:
{sendfile, Offset, Length, Filename}根据偏移量或长度的值,可以发送整个文件,也可以只发送一部分。 即使发送整个文件也需要这个长度。Cowboy在 content-length 头中设置。
Response = cowboy_req:reply(200, #{
<<"content-type">> => "image/png"
}, {sendfile, 0, 12345, "path/to/logo.png"}, Request).7.信息化返回值
Cowboy可以发送信息响应。信息响应是状态码在100到199之间的响应。任何数字都可以在正确的响应之前发送。发送一个信息响应并不会改变正确响应的行为,客户端应该忽略任何他们不理解的信息响应。
下面的代码段发送了103个信息响应,其中包含一些预期在最终响应中出现的头信息。
Response = cowboy_req:inform(103, #{
<<"link">> => <<"</style.css>; rel=preload; as=style, </script.js>; rel=preload; as=script">>
}, Request).这些概念可能都难以理解,主要我们平时的日常开发都是以应用为主,而没有多接触过规范,上面讲的这个Informational responses,可以在HTTP的RFC文档中找到。
8.Push
HTTP/2协议引入了推送与响应中发送的资源相关的资源的能力。Cowboy为此提供了两个数:cowboy_req:push/3,4。Push只适用于HTTP/2。如果协议不支持它,Cowboy将自动忽略push请求。
push函数必须在任何应答函数之前调用。否则会导致崩溃。要推送资源,您需要提供与执行请求的客户机相同的信息。这包括HTTP方法、URI和任何必要的请求头。
Cowboy默认情况下只需要您提供资源和请求头的路径。URI的其余部分取自当前请求(不包括查询字符串,设置为空),该方法默认为GET。
下面的代码段推送一个在响应中链接的CSS文件 :
cowboy_req:push("/static/style.css", #{
<<"accept">> => <<"text/css">>
}, Request),
Response = cowboy_req:reply(200, #{
<<"content-type">> => <<"text/html">>
}, ["<html><head><title>My web page</title>",
"<link rel='stylesheet' type='text/css' href='/static/style.css'>",
"<body><p>Welcome to Erlang!</p></body></html>"], Request).要覆盖方法、方案、主机、端口或查询字符串,只需传入第四个参数。下面的代码段使用了不同的主机名:
cowboy_req:push("/static/style.css", #{
<<"accept">> => <<"text/css">>
}, #{host => <<"cdn.example.org">>}, Req),推送的资源不一定是文件。只要推送请求是可缓存的、安全的,并且不包含正文,就可以推送资源。在底层,Cowboy处理推入的请求与处理普通请求相同:创建一个不同的进程,该进程最终将向客户机发送响应。
Push是http2的一种规范,更多内容请看这里:https://segmentfault.com/a/1190000009782985
13.Using cookies:使用HTTPCookie
14.Multipart:文件处理
15.REST principles:Rest设计规范
16.Handling REST requests:处理Rest请求
17.REST flowcharts:流式Rest请求处理
18.Designing a resource handler:设计一个资源处理器
19.The Websocket protocol:Websocket
20.Websocket handlers:Websocket处理器
21.Streams:流式处理
22.Middlewares:请求中间件
大家对于中间件可能有不同的理解,主要是目前很多框架对于中间件的叫法不一样。比如Python世界里,中间件就是用来拦截用户请求的,但是JavaWEB世界,中间件则泛指消息队列。而拦截请求的组件通常又叫拦截器。
对于Cowboy的中间件,大家可以按照自己的技术栈的名词进行理解即可。
为了加深大家对中间件的理解,拿Java拦截器作为案例来对比学习。
class Interceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
return false;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
}
}Java同样是实现了一个类,重写preHandle, postHandle,afterCompletion方法。其中如果preHandle返回false,则终端请求,返回true则继续。
对于Cowboy来讲,则是实现另一个行为模式: cowboy_middleware 。它也有类似的一套规则。
-module(index_middleware).
-author("wangwenhai").
-behaviour(cowboy_middleware).
%% API
-export([execute/2]).
execute(Request, Env) ->
{ok, Request, Env}.
配置中间件
{ok, _} = cowboy:start_clear(http_listener,
[{port, Port}],
#{env => #{dispatch => Dispatch},
middlewares => [cowboy_router, index_middleware, cowboy_handler]
}
),其中execute函数的返回值决定了是否继续本次请求:
{ok, Req, Env}继续本次请求{suspend, Module, Function, Args}当前请求重定向到另一个MFA{stop, Req}直接终止请求
{suspend, Module, Function, Args}会丢失所有之前的参数和堆栈信息。
中间件环境被定义在env参数。它是一个元组列表,第一个元素是atom,第二个元素是任何Erlang项。
环境中保留两个值:
listener:包含前面的监听器的名称result:包含进程信息
其中listener始终都包含值,result可以被任何一个中间件设置。 如果设置为ok以外的任何值,Cowboy将不处理此连接上的任何后续请求。
Env一般可以用来设置一些环境变量。 可以通过调用cowboy:set_env/3便利函数来更新环境,在环境中添加或替换一个值。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!